I Tried to Make AI Output World-Class. Here's What Actually Happened.

A multi-day experiment in context engineering, multi-agent pipelines, and the gap between "good enough" and genuinely excellent AI output.
TL;DR: I spent ~$5 and 500+ LLM calls trying to systematically push AI output from good to world-class across three domains. The most humbling finding: my hand-built debugging knowledge base made the model worse at debugging. It already knew more than I was teaching it. For landing page copy, no single prompt won everywhere. The trick was routing, picking the right strategy for each visitor type. For UI design, iterative revision improved individual elements but couldn't crack visual coherence without a design system defined upfront. The thread connecting all three: a weaker model with the right setup beat a stronger model with the wrong one.
The Question
It started with a landing page CTA.
I was building Menu Decoder (link opens in a new window), a travel app that helps people with dietary restrictions navigate foreign menus. I asked Claude to write the copy. It produced:
Ready to get started? Try the app and see what it can do for you. Try Menu Decoder
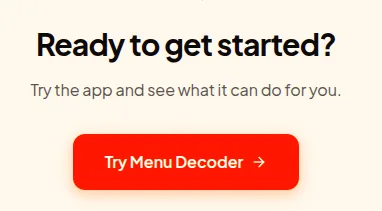
This is technically fine. It is also completely useless. It could be the CTA for a weather app, a recipe tool, a budgeting spreadsheet. It has no relationship to the specific fear a person with a peanut allergy feels when staring at a Thai menu they can't read.
I asked Claude to try again, this time focused on what the app actually solves. It produced:
Scan any menu. Know what's safe. Point your camera at a foreign menu and get instant allergen alerts in your language. Scan a Menu Now
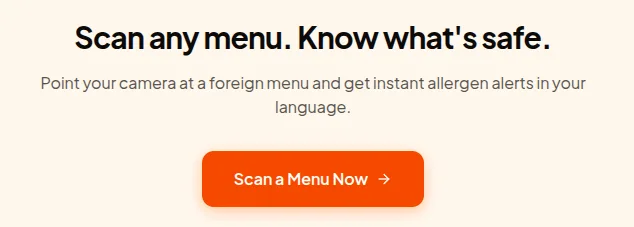
Better. Obviously better. But I hadn't changed the model or the context. I had just given it better direction. Which raised the question that consumed the next several days:
Is there a systematic process for making AI produce genuinely excellent output? Or does it always require a human expert to point it in the right direction?
The Hypothesis
My initial assumption was straightforward: LLMs are generalists. They know a lot but not deeply. The path to world-class output should look something like how humans become world-class experts. Acquire deep domain knowledge, develop judgment, apply it to specific problems.
So I set out to build what I called a "latent space activator," a framework that would, through careful context engineering, transform a generalist LLM into a domain expert capable of producing top 1% output.
I started with code debugging, then landing page copy, then UI design. The experiment ran for several days, 500+ LLM calls, and cost roughly $15 in API fees.
The results were not what I expected.
Experiment 1: Code Debugging
Why This Domain
Code debugging has a property that makes it ideal for experimentation: ground truth exists and is unambiguous. Code either runs or it doesn't. A bug is either fixed or it isn't. You don't need human judges or conversion metrics. You need a terminal.
I built a three-layer pipeline:
-
Knowledge Base: four markdown files encoding debugging expertise from first principles. What a bug actually is (a divergence between mental model and system reality), eight root cause classes with correct and incorrect fixes, anti-patterns, decision trees.
-
Latent Space Activator: a system prompt that encoded not just knowledge but reasoning process. Classify before diagnosing, form falsifiable hypotheses, reason from invariants not symptoms.
-
Multi-Agent Pipeline: Generator produces a diagnosis, Critic adversarially challenges it, Arbitrator resolves the dispute. The theory was that adversarial review would improve output quality.
I tested this against eight code problems (quadratic complexity bugs, mutable default arguments, race conditions, closure capture issues) across four models and four configurations, 356 runs total.
What the Data Said
The first surprise: the knowledge base made things worse.
| Config | Expert Rate |
|---|---|
| Bare model (no KB, no agents) | 92% |
| KB only | 85% |
| Full pipeline (KB + agents) | 93% |
The bare model outperformed the KB-only configuration. Adding carefully crafted expert knowledge about debugging made the model worse at debugging than it was without any help.
The explanation, once visible, was obvious: the model already had this knowledge. It had been trained on every debugging tutorial, every Stack Overflow answer, every textbook on algorithms. The KB didn't add knowledge. It competed with knowledge the model already held, in a slightly different vocabulary, producing interference.
The second surprise: all models, all configurations, all eight problems produced a 100% code execution pass rate. The problems were solved correctly every time regardless of architecture. The domain was simply within the native capability of current models.
The Real Finding
The original hypothesis, that architecture could substitute for model quality, couldn't be tested here because there was no gap to close. Current frontier models solve production-grade debugging problems reliably without any help.
The finding that mattered: KB scaffolding is net-negative when the model already has the expertise. You can't improve on what's already there by telling it how to think. You can only interfere.
Experiment 2: Landing Page Copy
A Different Kind of Problem
Landing page copy has a property that makes it structurally different from code: the ground truth is slow (conversion rates take weeks to measure), subjective (what's world-class for B2B SaaS isn't world-class for consumer fintech), and contested (experts disagree).
Instead of A/B testing, I built a judge. An LLM scoring output on five dimensions:
- Visitor emotional accuracy: does the copy name the actual fear the visitor arrives with?
- Specificity: is this copy specific to this product, or could it be any competitor's?
- Mechanism clarity: does the visitor understand HOW the product solves the problem?
- CTA-awareness match: does the call to action ask for the right level of commitment?
- Interchangeability: could this copy be used by a competitor unchanged?
Six products, four configurations, 30+ runs. Products included Moz, Crazy Egg, GoHenry, Smart Insights, Sunshine.co.uk, and Course Hero, all drawn from documented conversion case studies with real lift numbers, not taste-based selection.
The Routing Discovery
No single configuration won across all products. But a clear pattern emerged when I sorted by visitor awareness level:
Cold traffic (visitor doesn't know the product exists): question_first won by a significant margin. GoHenry, a fintech product for children marketed to anxious parents via social media, scored 7.4 with question_first vs 6.2 bare. Forcing the model to articulate the visitor's emotional state before writing produced copy that named the specific tension parents feel: wanting their children to develop real financial skills while being terrified of real financial exposure.
"Give Your Child Real-World Money Skills, Without Real-World Risks."
That headline emerged from question_first. Bare generated: "Introducing GoHenry: The Smart Way to Teach Kids About Money."
Hot traffic (visitor ready to buy): bare won. Sunshine.co.uk, a budget travel site where the conversion barrier was skepticism about prices that seemed too good to be true, scored 7.4 bare and 6.0 with question_first. The visitor already knows what they want. Emotional probing adds noise. Specifics close.
Products with rational barriers (value vs free alternatives): mechanism_first was the critical intervention. Smart Insights, a digital marketing education platform competing against free content, went from 5.4 GENERIC with question_first to 7.2 COMPETENT with mechanism_first. The key sentence that appeared: "Get the depth of a marketing consultant at a fraction of the cost." That's the mechanism. It reframes the product from "another education platform" to "consultant alternative."
The Ceiling
Nothing broke 8.0. The best generated copy scored 8.4, and that was on my actual product, Menu Decoder, using the routed pipeline with Sonnet + mechanism_first.
"AI that reads what's not on the menu"
Snap a photo of any foreign-language menu and get instant safety alerts, even for hidden ingredients never listed on the page.
The judge gave this 9/10 for visitor emotional accuracy, 9/10 for specificity, 9/10 for interchangeability. The one weak score: 7/10 for CTA-awareness match, because the copy asks cold traffic to buy immediately without a lower-commitment first step.
The judge was right. The copy earned the click. The product flow has to earn the conversion. Copy can't fix a paywall that asks too much.
The Key Insight
The most important finding from the copy experiment wasn't about prompts. It was about the relationship between model quality and architecture value:
Running the same pipeline on Sonnet vs Gemini Flash showed that the interaction between model and configuration matters more than either alone. Sonnet with kb_scaffold produced WORLD_CLASS copy for Course Hero. Sonnet with bare produced worse copy than Gemini Flash with bare on Sunshine. A better model with the wrong configuration underperforms a weaker model with the right one.
Experiment 3: UI Design
The Setup
Default Claude Code UI output is competent and consistent. It is also visually identical across every project. Tailwind cards with shadow-md, blue-500 accent color, rounded-xl on everything. You can tell it's AI-generated not because it's bad but because it has no identity.
I wanted to know: can context engineering produce genuinely distinctive UI design? Or is the generic aesthetic a hard ceiling?
I built a pipeline that rendered generated Astro components in a browser using a Vite dev server, took Playwright screenshots, and evaluated them with a multimodal judge receiving the actual rendered screenshot.
The test case: Menu Decoder's main scan screen. Camera viewfinder, dish list with safety badges, FAB.
Test 1: What Activates Better Design
Four conditions, same functional spec, one variable changed per condition:
bare: White background, rounded cards, blue FAB, small pill badges. Classic default Tailwind. Shadow count: 2. Blue/indigo count: 2.
product_context: Describe the user's emotional state. Anxious traveler, dietary restriction, foreign restaurant. Visual output: identical to bare. Zero change. Describing the user does not activate visual capability.
reference_style: Specify the aesthetic target. Dark background, no shadows, no blue, Linear/Vercel aesthetic. Shadow count: 0. Blue/indigo count: 0. Dark background, translucent badge fills, sharp corners. A completely different design language activated by three sentences of style direction.
full_brief: Product context + style direction + explicit anti-patterns. The standout difference from reference_style: solid full-height color blocks for safety badges (bright green, amber, red) filling the right side of each dish row. The design comment at the top of the generated file read: "The safety badge must be the dominant visual element in each row." It was executed.
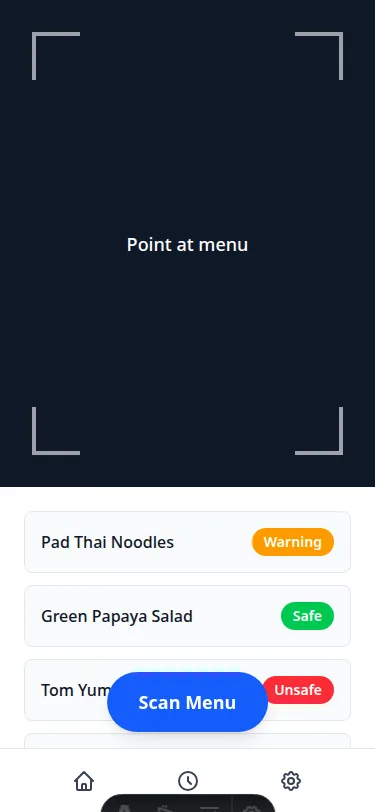
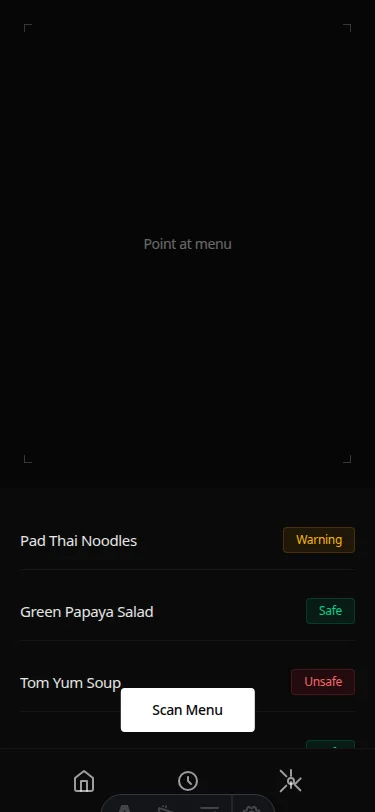
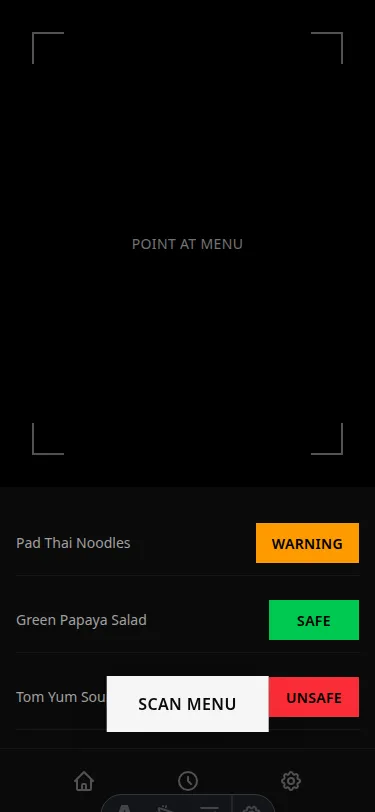
The activating variable is visual style direction, not product understanding. Telling the model what the user feels does nothing. Telling the model what the screen should look like does everything.
Test 2: The Feedback Loop
I built an iterative revision loop: generate, screenshot, judge critique, revise, repeat twice. The judge was given the rendered screenshot and asked to identify the most important thing to fix, with a specific implementation instruction.
The revision instructions were excellent:
"Move the SCAN MENU button from its current centered bottom position to a fixed position at the bottom of the viewfinder area. The dish list must never be obscured by interactive elements."
"Replace small right-aligned pill badges with full-height color blocks that fill the entire right portion of each dish row. Apply the safety color to a div with absolute right-0 top-0 h-full w-20 containing centered white text."
The model executed both instructions. The layout improved measurably. And then something interesting happened: the visual coherence degraded. Locally correct decisions (FAB moved up, badges widened) produced a globally incoherent layout. A card container appeared around the dish list for no clear reason. The viewfinder got compressed awkwardly. The design started to feel assembled from competing decisions rather than designed from a unified logic.
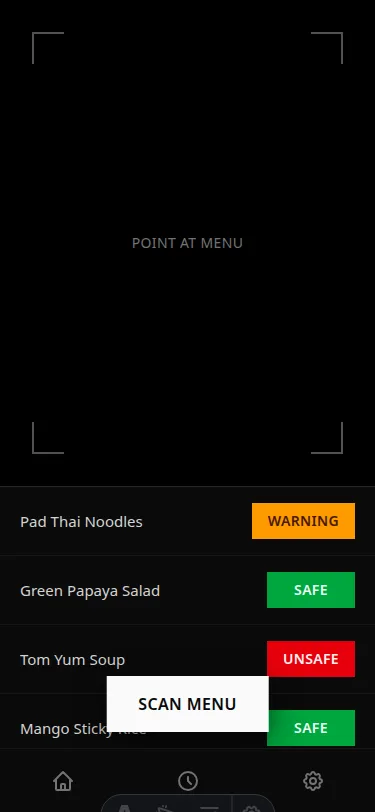

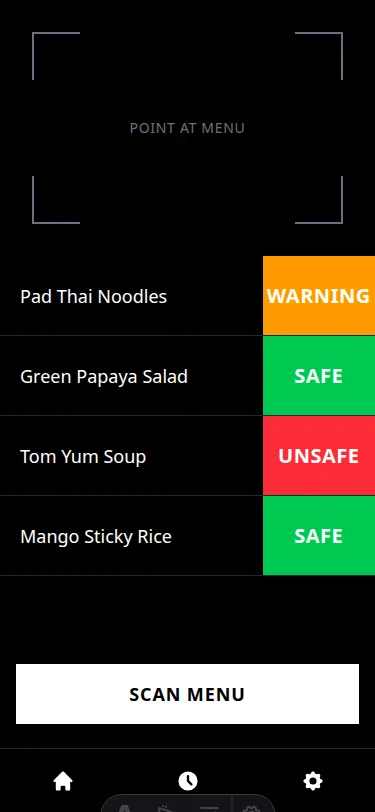
The score went from 5.2 to 6.4 and then stopped moving.
The Structural Finding
The revision loop worked at the element level and failed at the system level. Which revealed the real problem: there is no design system.
Every world-class product UI is built on a design system. Color tokens named by function, a typographic scale, a spacing unit, a component language. A designer doesn't design a screen; they define a system and then apply it.
The model is being asked to simultaneously define a design system and build a screen. Under that cognitive load, it defaults to its training distribution: Tailwind defaults. The revision loop makes individual decisions more correct without ever establishing the system that would make them coherent.
The correct pipeline architecture, not yet built but clearly indicated by the evidence, is:
Phase 1 (once per brand): Given a product brief, generate a design system specification. Color tokens. Type scale. Spacing unit. Component language. One sentence describing the visual identity.
Phase 2 (per screen): Given the design system spec + functional spec, build the screen. Every decision references the spec.
Phase 3: One targeted revision pass. Screenshot, specific instruction, revise once.
What Three Experiments Actually Proved
Finding 1: The assumption was wrong
The original hypothesis, that LLMs need to be taught domain expertise through context engineering, is wrong for well-covered domains. Current models already have world-class expertise in code debugging encoded in their weights. The architecture added nothing and sometimes subtracted.
The corrected hypothesis: context engineering adds value where the model has genuine capability gaps, not where it has latent expertise being suppressed. The KB helped weaker models on specific problem types. It hurt stronger models on problems they already understood.
Finding 2: The expert's attempt to help can make things worse
The KB was built by someone reasoning carefully about debugging expertise. It made outputs worse. The model's native representation of the domain was better than the expert's explicit encoding of it.
This has an uncomfortable implication: a domain expert trying to engineer the model's context might systematically underperform a non-expert who just asks the model directly. The expert's mental model competes with the model's better one.
Finding 3: Routing beats universal optimization
There is no single best configuration across domains. question_first wins for cold traffic. bare wins for hot traffic. mechanism_first wins for rational barriers. few_shot wins for warm traffic with pattern-matchable products.
The pipeline that produces consistent excellence isn't a better universal prompt. It's a routing layer that selects the right intervention for the specific problem type. Classification before generation.
Finding 4: Architecture value is inversely proportional to model capability
This appeared in both the code and copy experiments. For the cheapest model, the architecture added 6+ percentage points of expert rate. For the frontier model, it added nothing or hurt.
The window in which "use a better prompt" beats "use a better model" is shrinking as inference costs drop. This doesn't mean prompting is useless. It means the ROI calculation changes, and the engineering cost of maintaining a complex pipeline should be weighed against the cost of upgrading the model.
Finding 5: The generation/revision loop is necessary but not sufficient for UI
Copy can be world-class in a single generation pass with the right activation. UI design cannot, because world-class UI requires a coherent system applied consistently, and single-pass generation under prompt pressure defaults to assembling from framework defaults rather than designing from first principles.
The iterative revision loop improves individual elements. It doesn't establish the system. A design system definition phase, before any screen is generated, is the missing step.
What I'm Building Next
The routing pipeline for landing copy is in production. Menu Decoder's landing page uses the output. The headline, "AI that reads what's not on the menu," came from this experiment.
The UI design pipeline needs the design system layer before it's useful. That's the next experiment, and it'll be driven by an actual deliverable: Menu Decoder needs a full UI, not just a test screen.
The code debugging findings have a different application: they suggest that for domains where models already have strong priors, the most valuable architectural contribution isn't a KB or a multi-agent pipeline. It's a selective reliability mechanism. A fast, cheap check that identifies the small percentage of generations that are genuinely uncertain, and applies review only there. Most generations don't need it. Some do. Knowing which is which is the real engineering challenge.
The total cost to run all experiments described in this post: $15 in API fees and 8 hours of compute time across several days of iteration.
The most expensive insight: sometimes the best thing you can do is get out of the way.
Built with Claude Code, OpenRouter, Bun, and Astro. Experiments run on Gemini Flash 2.0, DeepSeek R1, Qwen3 Coder, and Claude Sonnet 4.5.